Contribution involontaire au Plan France tropicale 2050
Chaque canicule offre à la France une redécouverte collective. Les températures montent, les plateaux télé s’équipent de cartes rouges, les préfets recommandent de boire de l’eau, les éditorialistes découvrent que certains métiers se pratiquent encore dehors, et le pays, dans un bel effort de mémoire sélective, se demande si le changement climatique ne serait pas en train d’avoir quelques conséquences.
Il faut pourtant rendre justice à l’État stratège: la France avait anticipé.
Pas en adaptant ses villes, ses horaires de travail ou ses arbitrages agricoles. Ce genre de détail relève toujours d’un prochain plan, d’une future mission interministérielle ou d’un rapport attendu à l’automne. Non: la France avait vu plus loin. Elle avait eu, très tôt, l’intuition que son avenir climatique se jouerait dans les agricultures du chaud. Pour s’y préparer, elle s’était donc dotée de colonies, de stations agronomiques tropicales, de filières de plantes de rente, puis d’instituts de recherche spécialisés.
On a longtemps cru que tout cela servait aux tropiques. C’était manquer d’imagination prospective.
Avec le recul, les dossiers canne, café, cacao, coton, hévéa ou manioc prennent une cohérence admirable: les administrateurs coloniaux croyaient organiser des empires agricoles; ils rédigeaient, sans le savoir, les annexes techniques du Plan France tropicale 2050; les agronomes tropicalistes croyaient partir en mission; ils préparaient le retour à domicile.
Le CIRAD, dans cette lecture généreuse de l’histoire, devient un service public d’avant-garde. Pendant des décennies, il aura entretenu une compétence sur les cultures chaudes, les saisons ingrates, les stress hydriques, et les systèmes agricoles qui ne vivent pas dans le confort d’un climat tempéré stable. Il suffisait d’attendre que la métropole se décide à rejoindre son propre terrain d’étude.
Le calendrier est presque parfait, du moins dans la petite fiction comptable qui sert ici de boussole. Les missions lointaines coûtent cher, les expatriations aussi, les tutelles demandent des économies, et l’arlésienne d’une fusion CIRAD-INRAe revient régulièrement hanter les couloirs. Pendant ce temps, la France métropolitaine découvre qu’elle pourrait avoir besoin de gens capables de réfléchir à l’agriculture quand l’eau manque, quand la chaleur insiste et quand les plantes cessent de respecter les habitudes régionales.
Quelques signaux tangibles existent déjà, ce qui rend la plaisanterie moins confortable : des essais bananiers ont été documentés dans le Roussillon et dans l’Hérault; d’autres articles signalent des expérimentations d’avocat, de mangue, de papaye, de goyavier ou de bananier dans certains microclimats du Sud. Ces exemples restent ponctuels, souvent protégés, très dépendants du gel, du vent, de l’eau et du marché. Ils suffisent pourtant à faire glisser l’idée du registre de la farce vers celui du symptôme.
On pourrait donc pousser la logique jusqu’au bout: rapatriement des tropicalistes, mutualisation des expertises, fermeture progressive de l’ailleurs, ouverture du grand chantier national de la France tropicale 2050.
Le titre ferait rire, puis il faudrait faire les cartes.
Car l’intérêt de cette plaisanterie est qu’elle se laisse tester. On peut prendre des espèces associées aux agricultures tropicales ou subtropicales, récupérer leurs seuils climatiques, puis regarder ce que deviennent leurs zones d’aptitude en France métropolitaine sous projections climatiques. Les plantes deviennent alors des instruments de lecture. Cette approche rejoint un résultat déjà documenté à l’échelle européenne: les zones agroclimatiques se sont déplacées vers le nord et ce déplacement devrait s’accélérer avec le changement climatique.
Les cartes d’aptitude ne disent donc pas où planter des bananes; elles indiquent où plusieurs cultures du chaud cessent d’être climatiquement absurdes. Une culture qui franchit un seuil dans un seul modèle raconte une anecdote. Plusieurs cultures qui franchissent un seuil dans plusieurs modèles commencent à raconter autre chose.
L’analyse présentée ci-dessous va dans cette direction: plusieurs périodes, plusieurs modèles climatiques, des espèces tropicales ou thermophiles, des scores d’aptitude et des cartes de synthèse. Elle ne prétend pas décrire une faisabilité agricole complète. Elle permet de poser une question plus étroite, mais plus nette que les habituelles images de thermomètres: où la France métropolitaine commence-t-elle à entrer dans des conditions qui rendent pertinentes des compétences longtemps rangées du côté des agricultures tropicales ?
L’hypothèse qui se dégage est moins celle d’une France tropicale uniforme que celle d’une France des marges chaudes. Certaines façades littorales, telles que la Bretagne, et méditerranéennes voient s’épaissir un portefeuille crédible de cultures thermophiles. Le signal le plus fort ne vient pas des espèces tropicales les plus spectaculaires, largement bloquées, mais de cultures plus plausibles comme le sorgho, le maïs tropical, l’avocat, le pois d’Angole ou le sésame. Cette hiérarchie rend l’exercice utile: le modèle ne valide pas un fantasme exotique, il montre un déplacement partiel des possibles agricoles, assez net pour troubler les catégories habituelles, mais encore fortement filtré par le gel, l’eau, l’altitude et la saisonnalité.
Ce ne sont pas des espèces étrangères à l’horizon scientifique du CIRAD. Certaines relèvent déjà de ses objets de recherche, de ses terrains, de ses filières ou de ses compétences historiques. La plaisanterie initiale devient alors moins confortable: ce que l’institution savait penser pour les agricultures du chaud pourrait devenir utile dans une métropole qui découvre que le chaud ne commence plus aussi loin.
Le CIRAD revient à la maison, donc. Non sous la forme d’un rapatriement en rangs serrés derrière l’INRAe, mais comme une ironie historique plus discrète: des savoirs constitués pour penser les agricultures du chaud deviennent soudain utiles dans un pays qui avait pris l’habitude de croire que le chaud commençait ailleurs.
Résultats
Un portefeuille agroclimatique qui s’épaissit sur les marges littorales

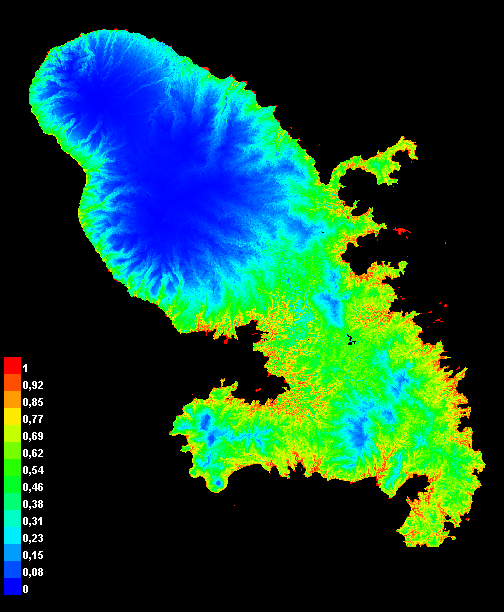
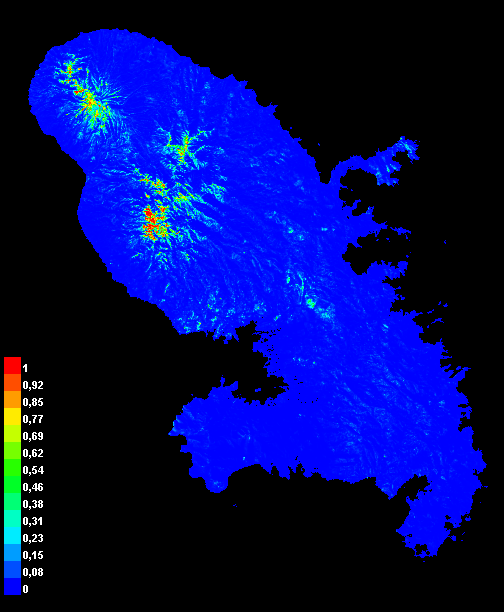
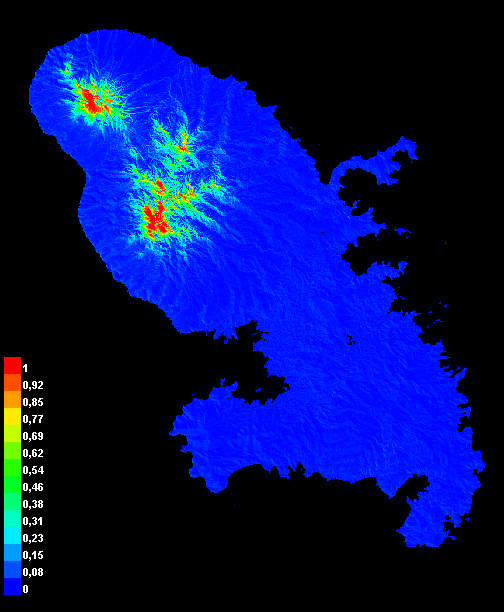
La figure montre une émergence progressive d’un véritable portefeuille agroclimatique de cultures du chaud en France métropolitaine. Sur la période historique 1995-2014, le nombre médian de cultures dépassant le seuil d’aptitude reste nul sur la quasi-totalité du territoire, à l’exception de quelques marges littorales déjà favorisées par des hivers plus doux. Dans les projections futures, le signal ne se diffuse pas uniformément vers l’intérieur, mais il s’intensifie fortement dans les zones où la contrainte de gel s’atténue: Bretagne, façade atlantique, littoral méditerranéen, Corse et certaines marges du Sud-Ouest. En fin de siècle, surtout sous ssp585, ces espaces ne présentent plus seulement une ou deux cultures marginalement plausibles: certaines portions significatives du territoire atteignent jusqu’à dix cultures avec un score Ecocrop médian supérieur ou égal à 50. Ce résultat donne corps à l’hypothèse centrale de l’article: la France métropolitaine ne devient pas uniformément tropicale, mais certaines régions entrent dans un domaine climatique où plusieurs cultures traditionnellement associées aux agricultures tropicales ou subtropicales cessent d’être anecdotiques du point de vue climatique. La persistance de vastes zones à zéro rappelle que l’extension reste filtrée par le gel, l’altitude et la saisonnalité, mais les foyers littoraux et méditerranéens suggèrent déjà un déplacement notable du portefeuille d’options agricoles sous climat futur.
Les cultures thermophiles les plus crédibles
Cinq cultures forment le noyau le plus convaincant de l’exercice. Elles ne relèvent pas toutes du registre “exotique”: avec le sorgho, le maïs tropical, le sésame et le pois d’Angole, on est d’abord face à des cultures thermophiles plausibles, auxquelles l’avocat ajoute une dimension subtropicale plus démonstrative. Ensemble, elles suggèrent que la “France tropicale” passe d’abord par des céréales, légumineuses, oléagineux et fruitiers du chaud, bien avant les cultures les plus spectaculaires.

Le sorgho est le signal le plus robuste: déjà présent sur les marges atlantiques et méditerranéennes dans l’historique, il progresse nettement dans le futur, surtout sous ssp585, avec une extension marquée sur la façade atlantique, le Sud-Ouest et une partie de l’intérieur occidental en fin de siècle. Le maïs tropical suit une dynamique proche, un peu moins ample, mais montre lui aussi un épaississement progressif des zones favorables sur l’Atlantique et en Méditerranée. Dans les deux cas, la carte parle moins de tropicalisation fantasmatique que d’un déplacement crédible du domaine des cultures adaptées à la chaleur. L’avocat offre un profil plus subtropical et beaucoup plus littoral, fortement structuré par la réduction du gel. Les scores élevés se concentrent d’abord en Méditerranée, en Corse et sur certaines zones atlantiques et bretonnes, puis s’étendent fortement sous ssp585 en 2071-2090, y compris sur une large partie de la façade atlantique et du Sud-Ouest. Le pois d’Angole est moins étendu, mais suit la même logique spatiale, avec un renforcement en Bretagne, sur l’Atlantique, dans le Sud-Ouest et autour de la Méditerranée. Son intérêt est important, car il renvoie à une légumineuse du chaud pertinente pour les enjeux de diversification et d’autonomie protéique. Le sésame reste le plus discret des cinq: les scores sont plus modestes et l’extension intérieure plus limitée, même si la fin de siècle sous ssp585 renforce nettement le signal sur l’Atlantique et dans le Sud.
Pris ensemble, ces résultats montrent qu’en fin de siècle, surtout sous scénario haut, plusieurs cultures du chaud atteignent simultanément des scores élevés sur des portions significatives de la façade atlantique, du Sud-Ouest, du littoral méditerranéen et de la Corse.

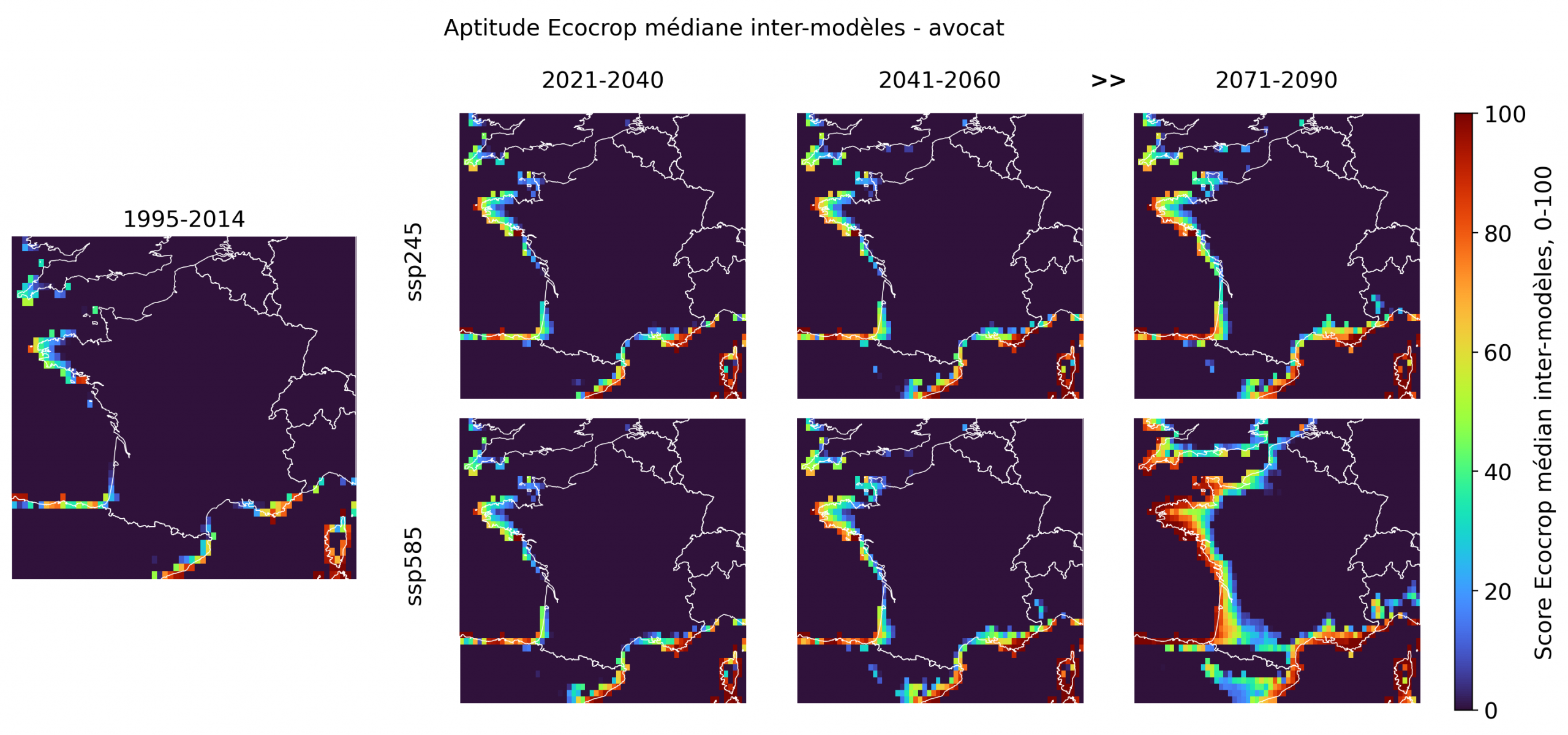
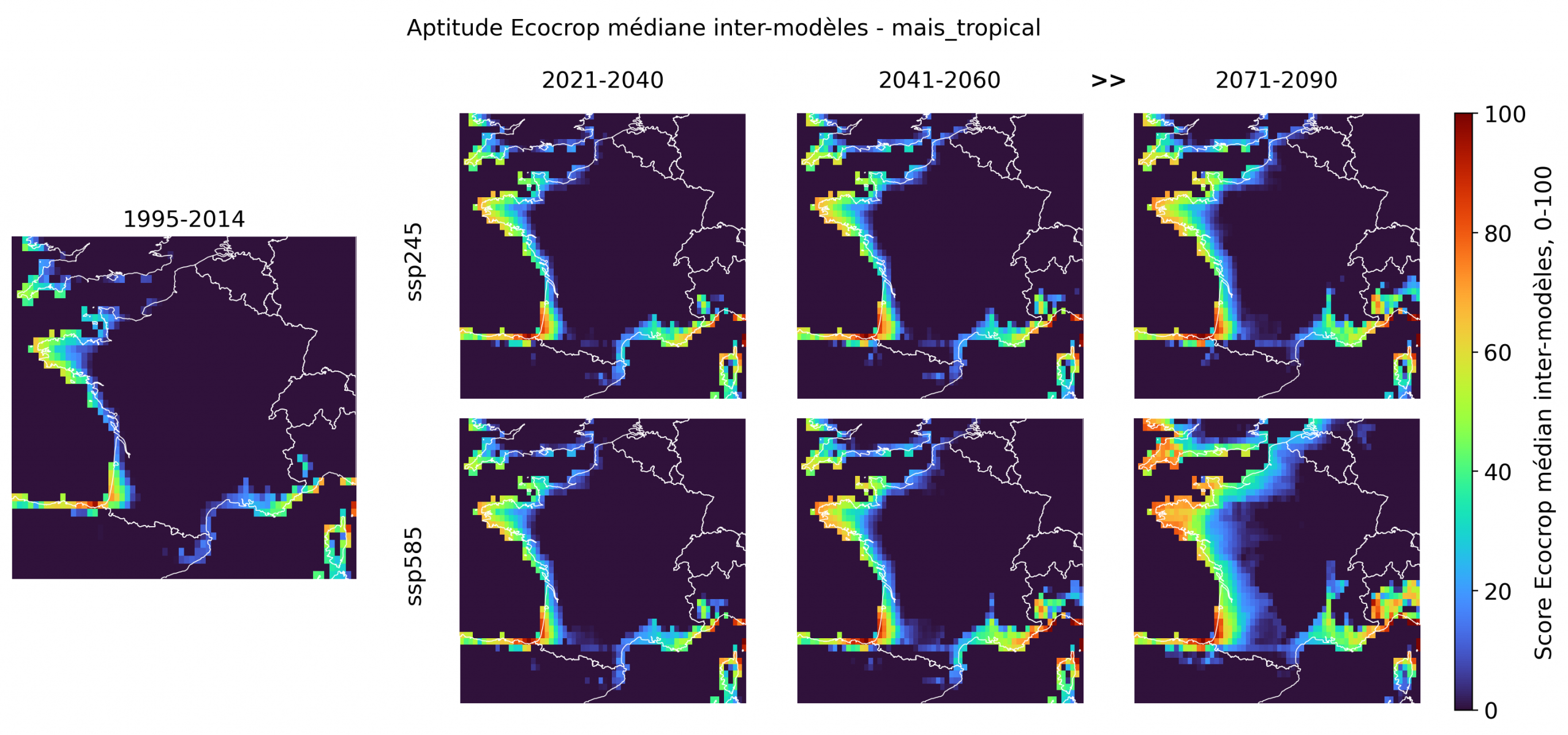
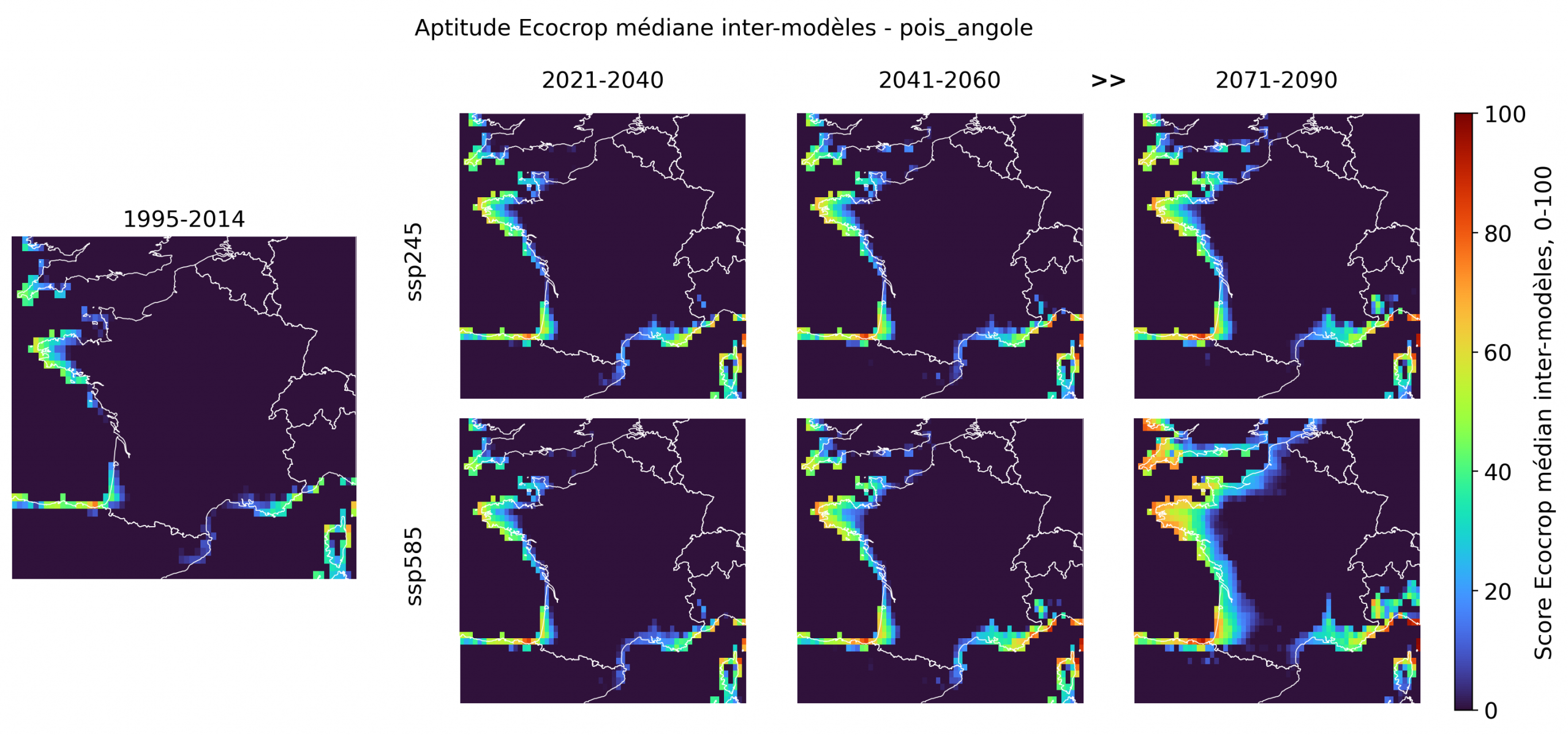
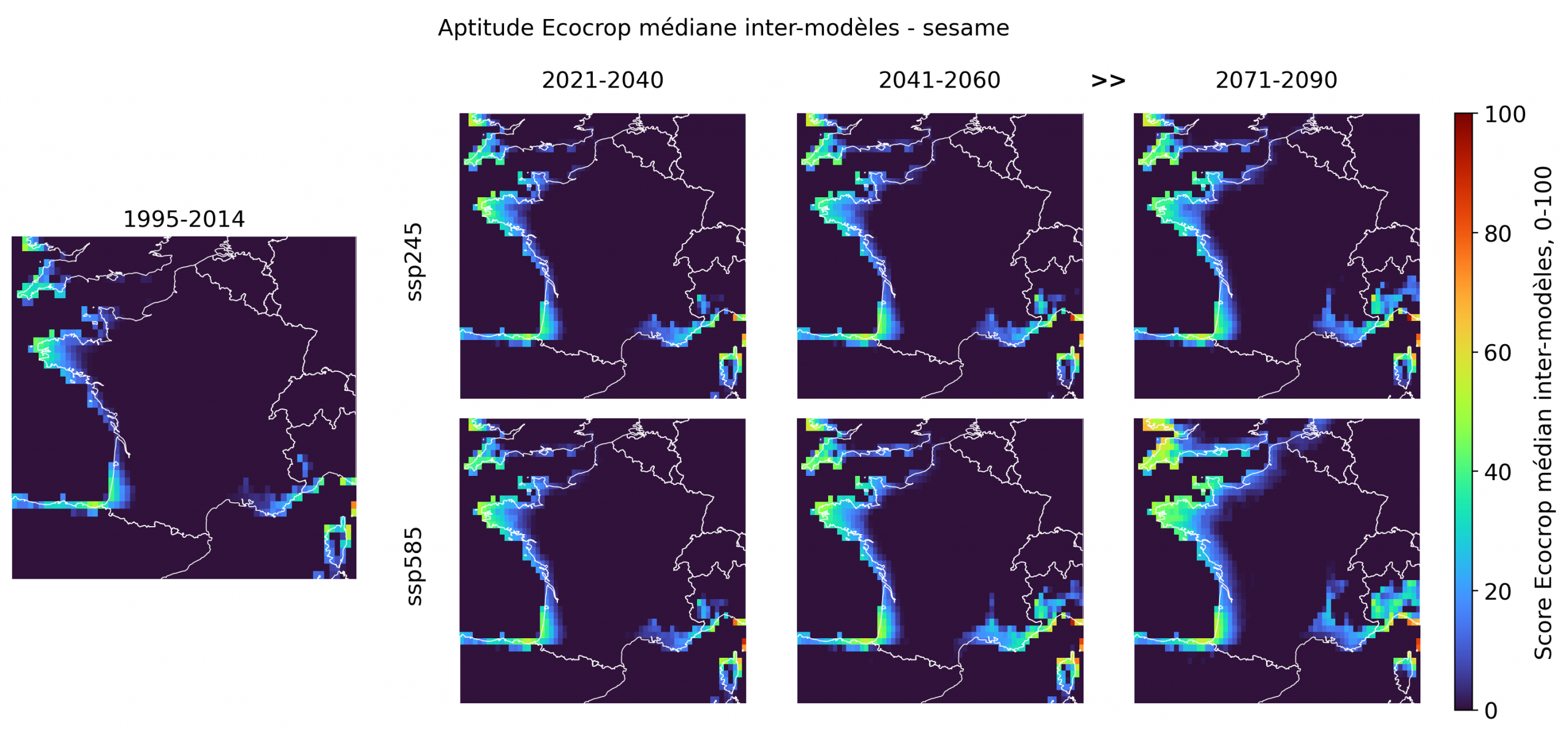
Des cultures de transition, visibles mais encore très contraintes

Pour ce groupe intermédiaire, l’aptitude progresse bien avec le réchauffement, mais sans atteindre la continuité spatiale observée pour le sorgho, le maïs tropical ou l’avocat. Le signal reste principalement cantonné aux zones littorales, avec une hiérarchie assez nette: les façades atlantiques et méditerranéennes jouent le rôle de zones d’entrée, tandis que l’intérieur du pays demeure largement défavorable, y compris en fin de siècle. Elles occupent une position intermédiaire: visibles dans les projections, parfois robustes localement, mais encore loin de former un domaine continu.
Le mil présente le signal le plus étendu de ce groupe. Il apparaît déjà faiblement sur les marges atlantiques et méditerranéennes en historique, puis gagne progressivement en amplitude, surtout sous ssp585 en 2071-2090. Son extension reste toutefois moins franche que celle du sorgho: les scores sont plus modérés et l’intérieur du territoire reste peu concerné. La mangue suit une logique plus subtropicale, avec des noyaux favorables sur la Méditerranée, la Corse, la Bretagne et certaines portions atlantiques. Sous ssp585 en fin de siècle, elle devient nettement plus lisible sur la façade atlantique et dans le Sud, ce qui en fait une bonne culture “signal” pour illustrer la montée d’un potentiel fruitier chaud sans basculer dans l’extrapolation généralisée.
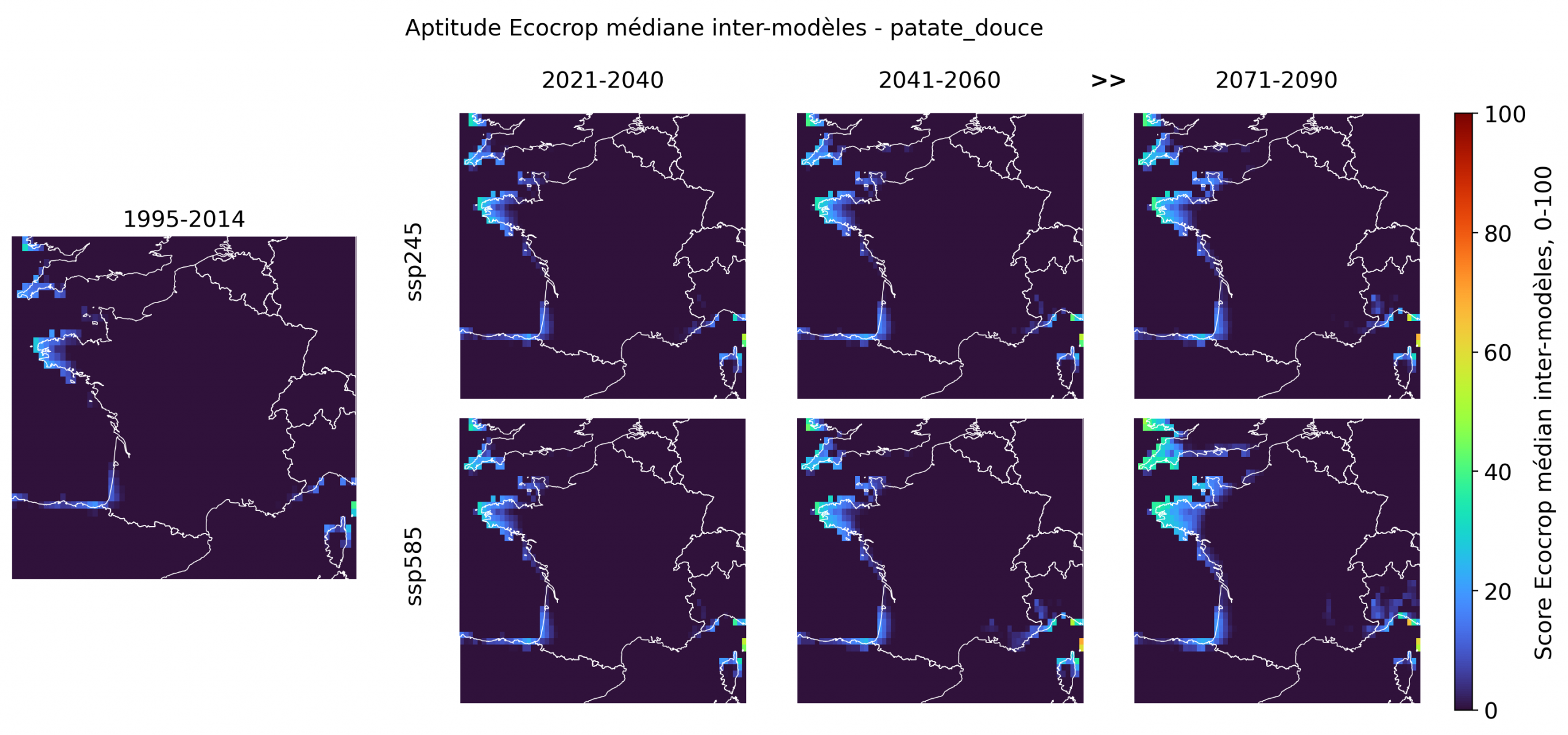
La patate douce et l’arachide restent plus discrètes. Elles montrent des foyers récurrents sur les littoraux doux, notamment Bretagne, Atlantique, Méditerranée et Corse, mais avec des scores généralement faibles à intermédiaires et une faible pénétration vers l’intérieur. Leur réponse au scénario haut est visible en fin de siècle, surtout sur les marges atlantiques, mais elle reste spatialement limitée. Ce comportement est intéressant: ces cultures sont souvent associées à des systèmes vivriers ou de diversification relativement plausibles, mais le modèle suggère que leur aptitude climatique médiane ne s’étend pas mécaniquement avec le réchauffement. Elles contribuent donc à nuancer le récit: l’élargissement du portefeuille tropical existe, mais toutes les cultures du chaud ne bénéficient pas de la même manière du déplacement climatique.
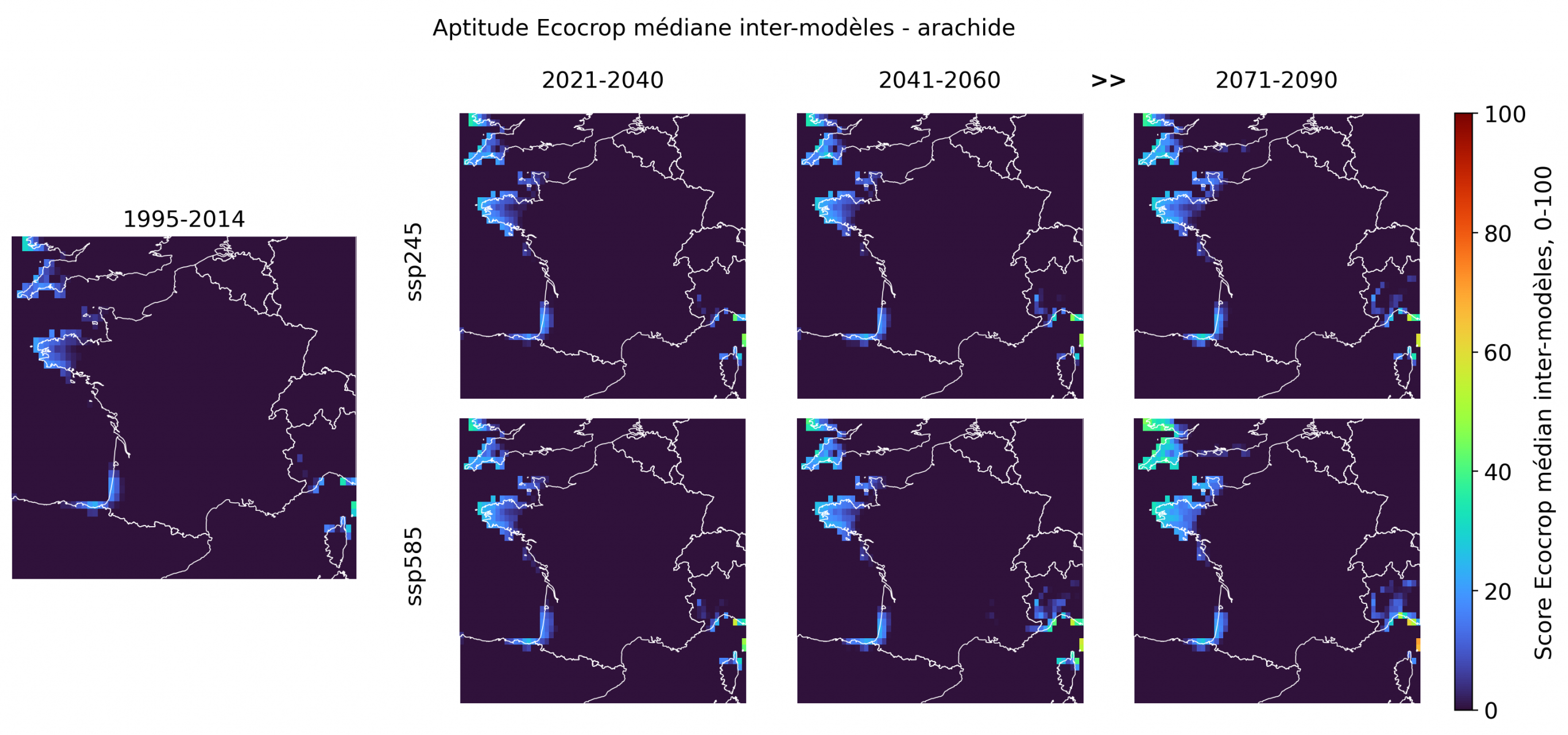
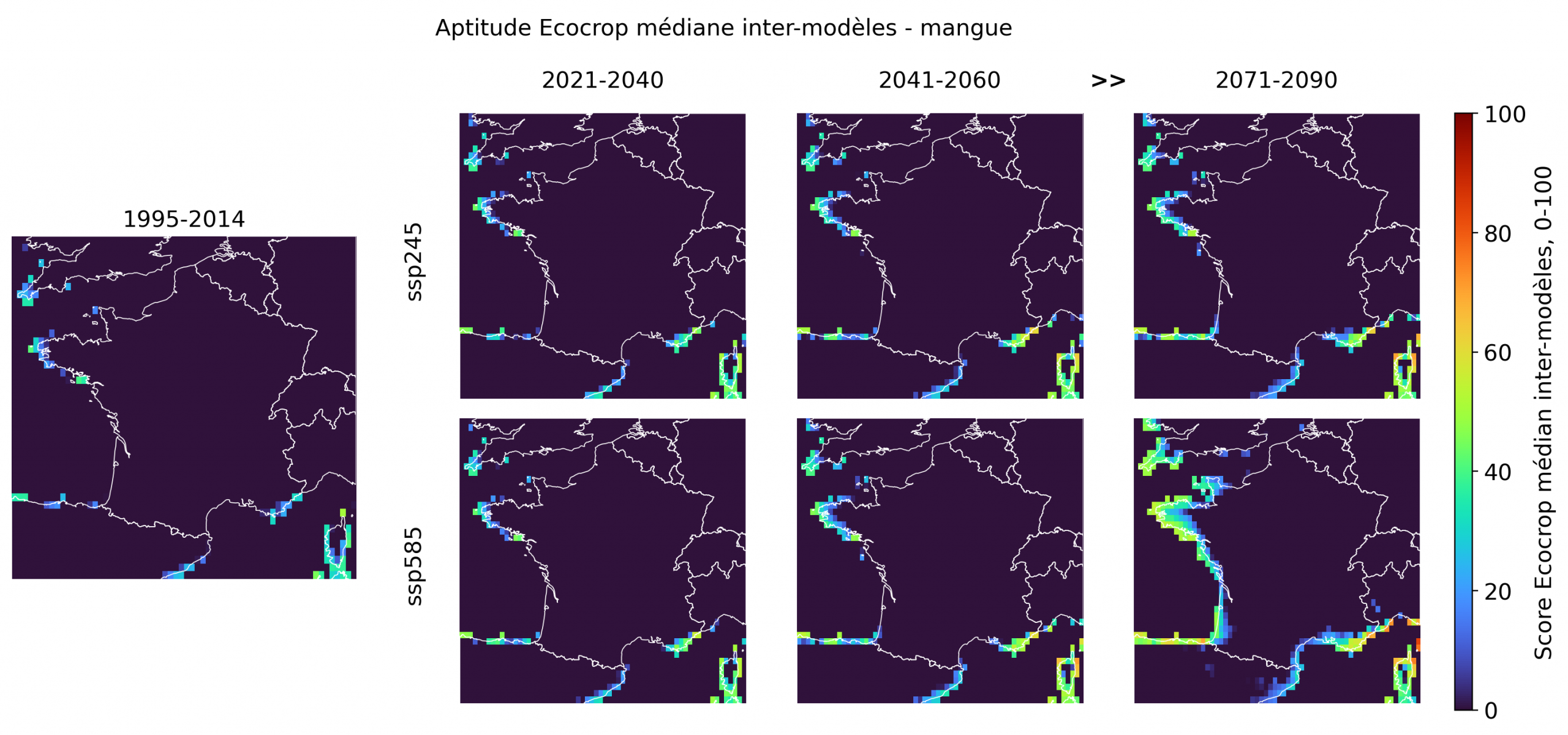
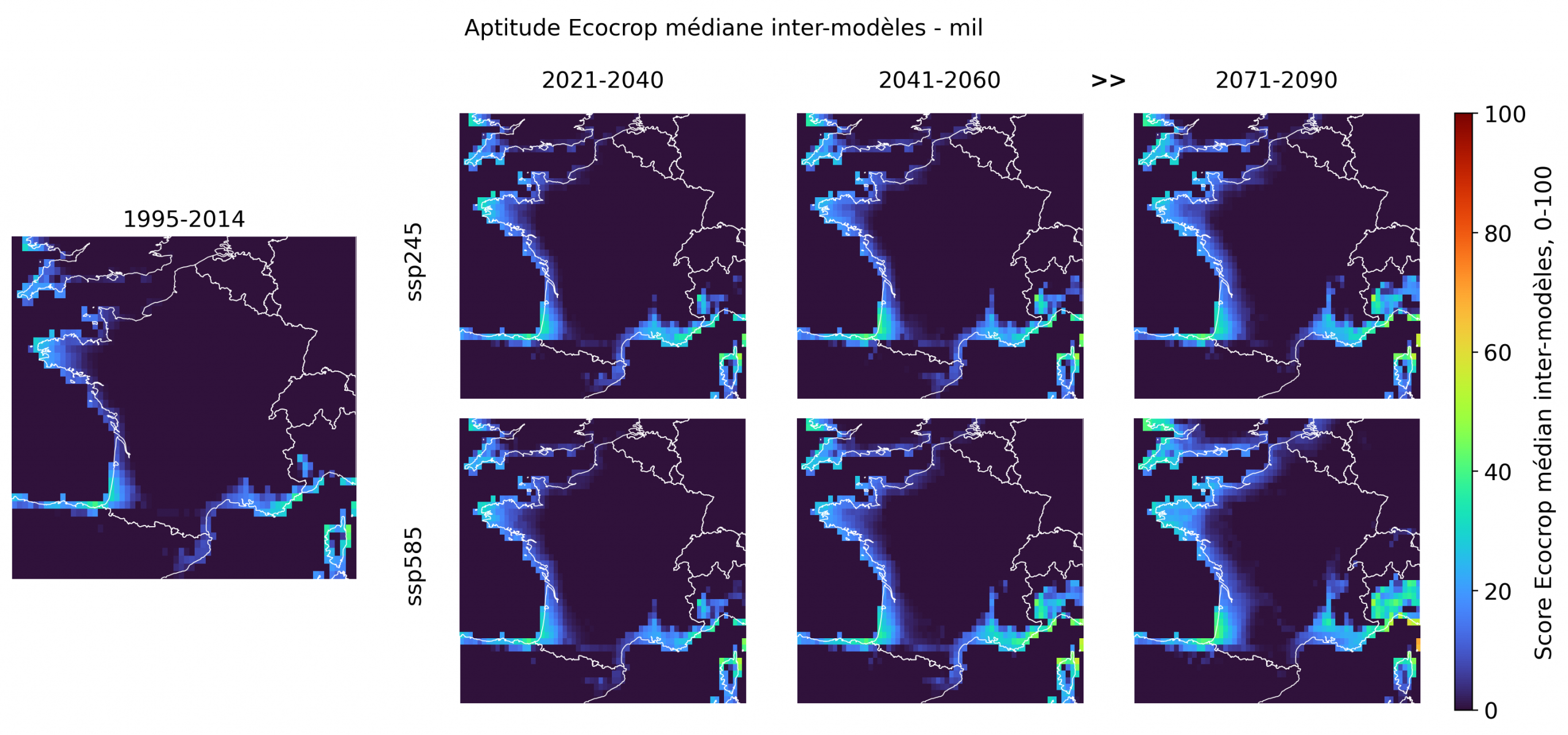
Les limites de la “France tropicale”
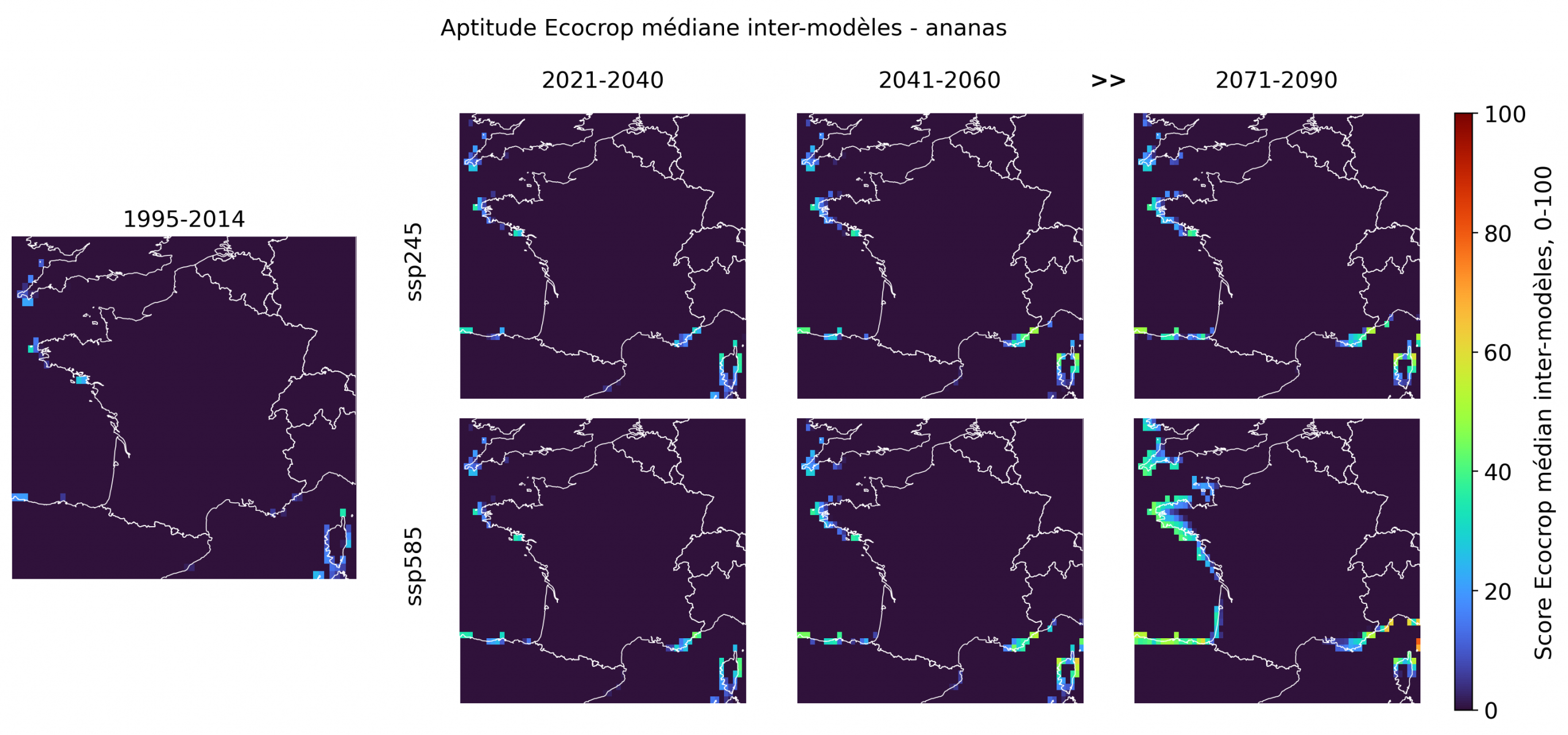
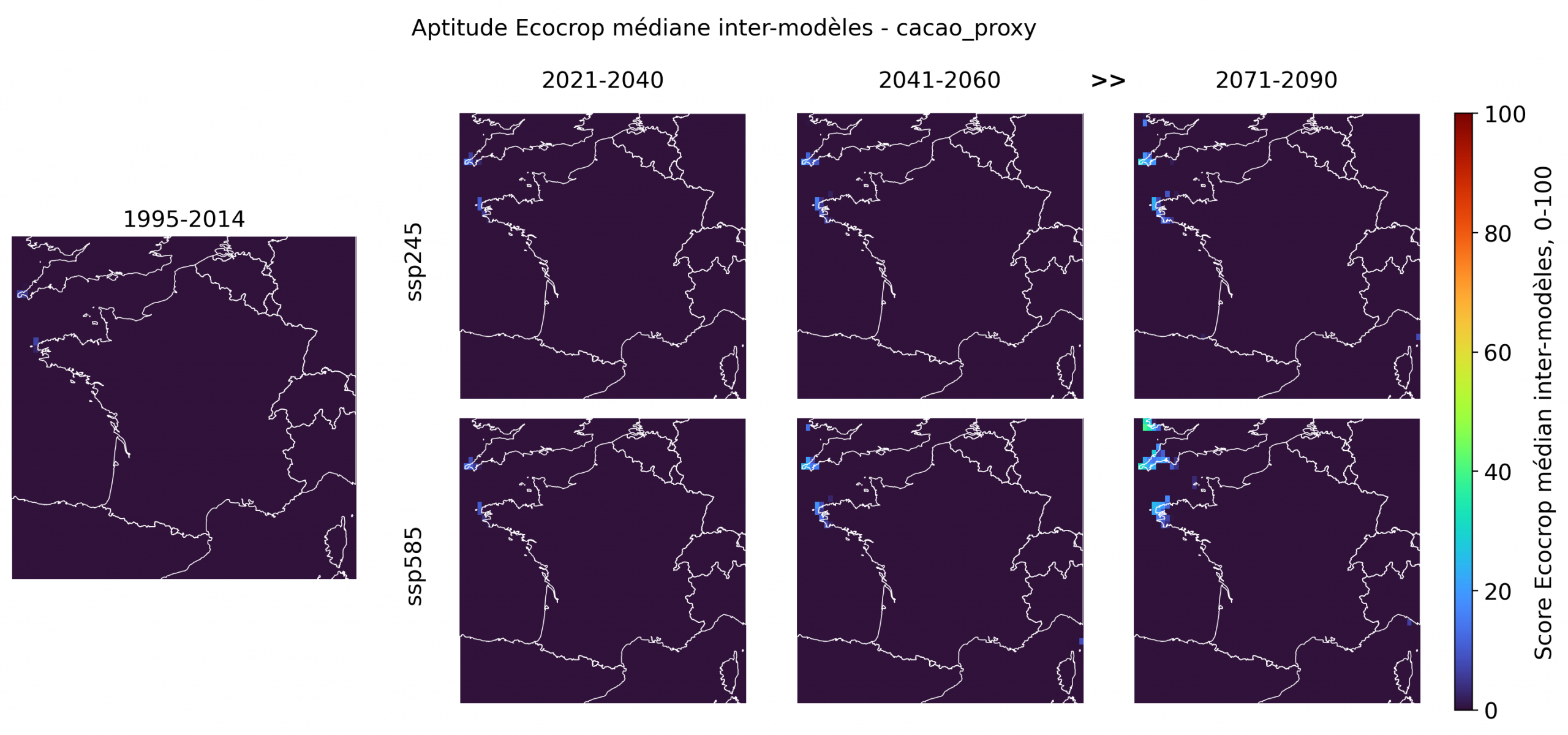
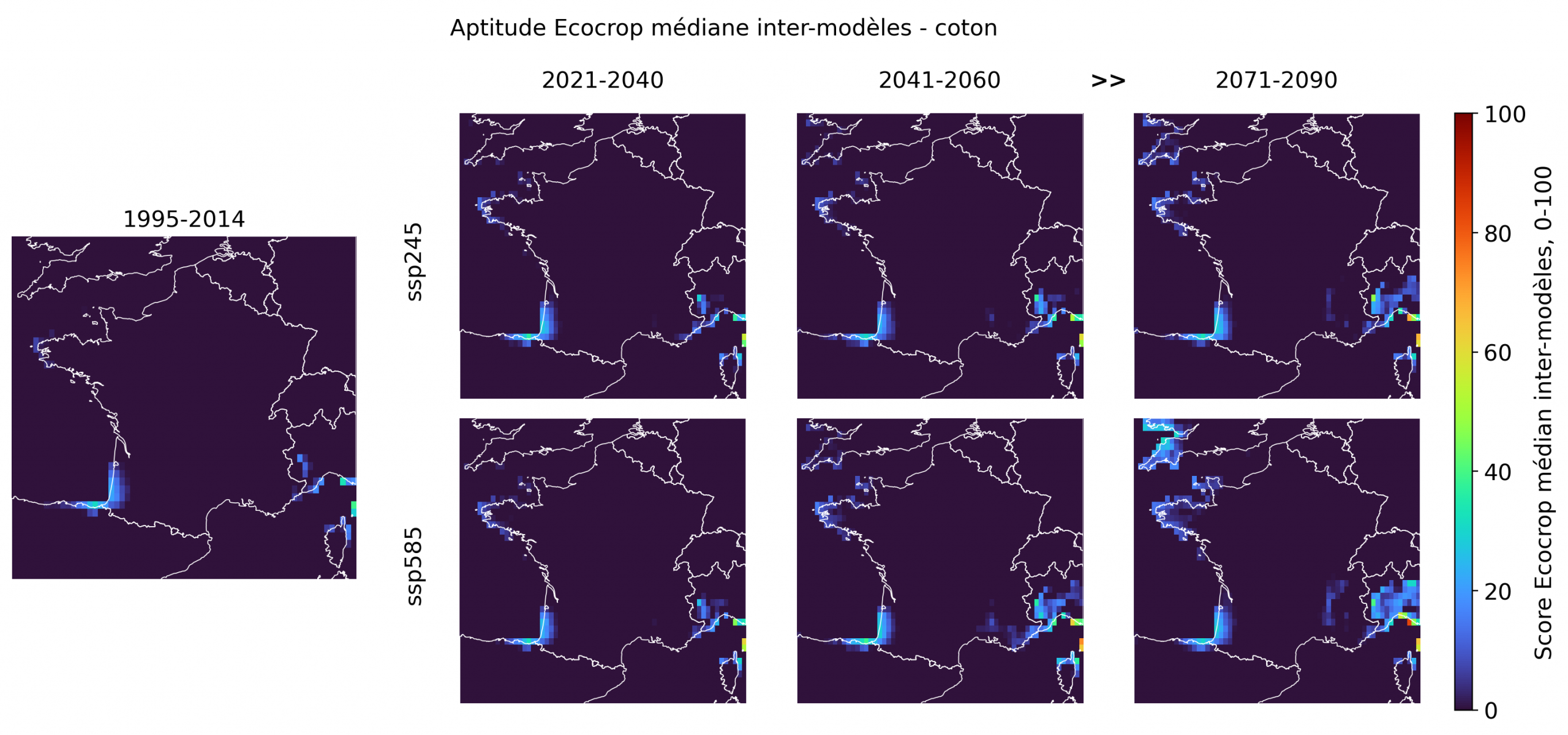
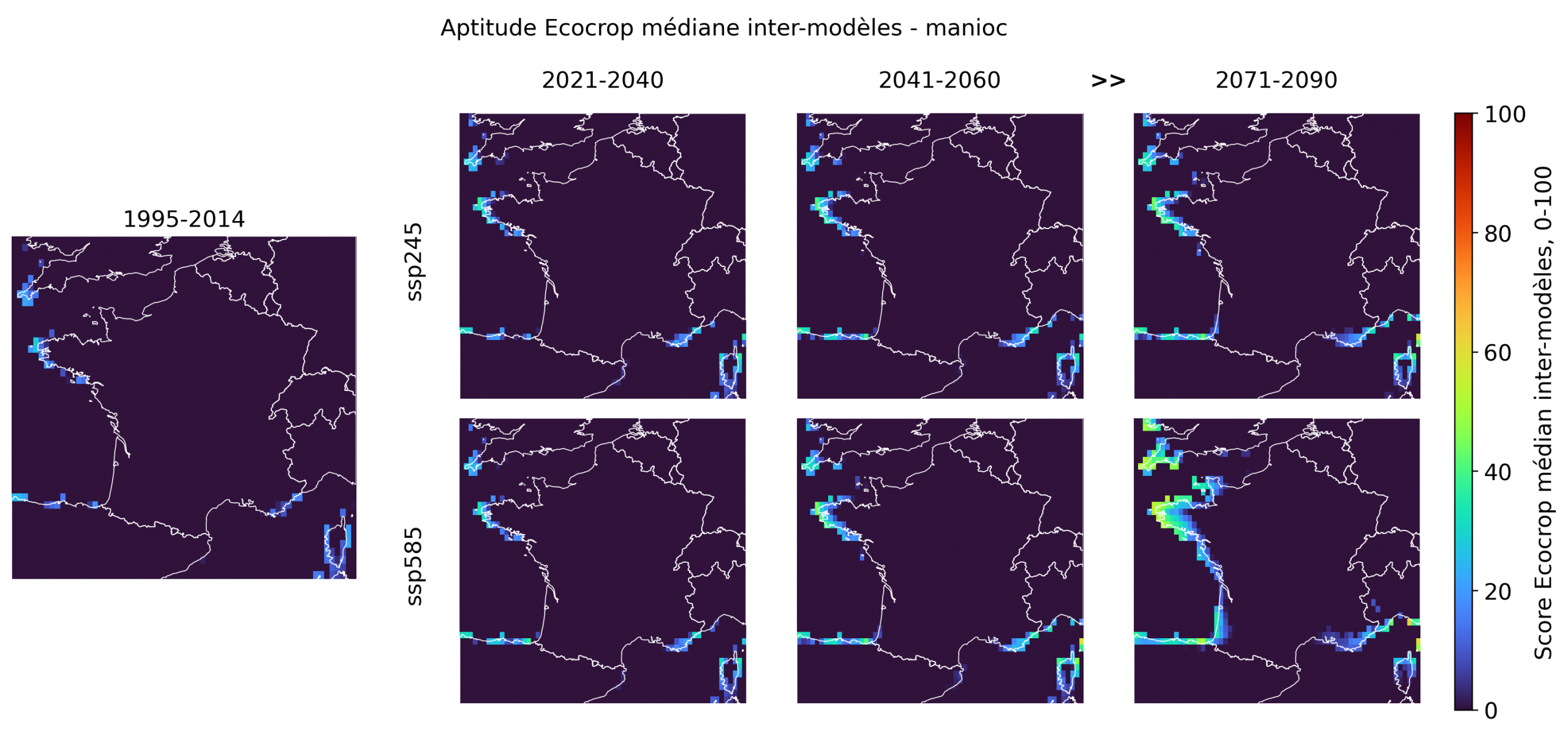
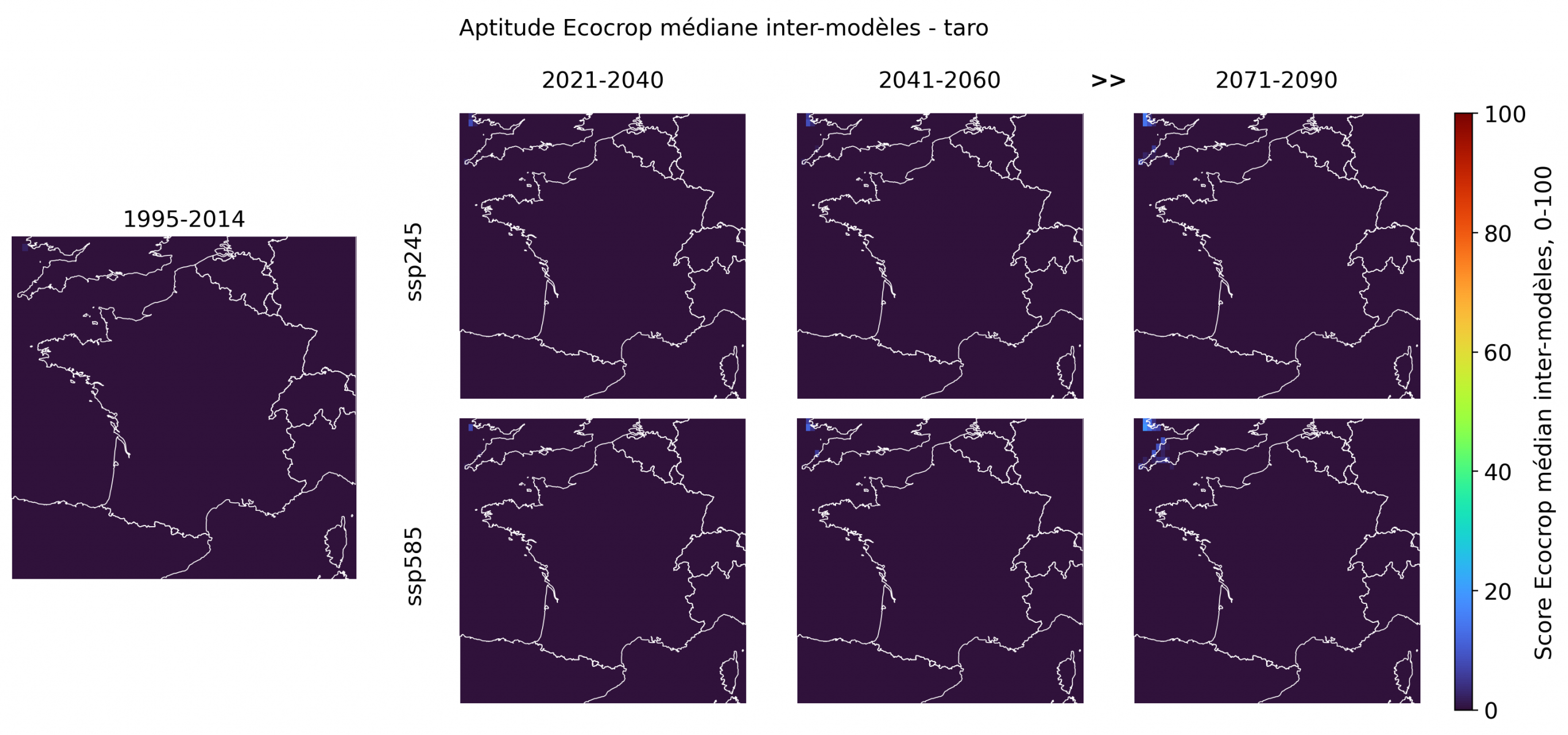
Les espèces aux scores faibles sont indispensables à l’interprétation: elles fixent les limites de la fiction tropicale. La plupart des cultures les plus emblématiques ou les plus franchement tropicales restent très peu aptes en France métropolitaine, même en fin de siècle. Le bananier, le taro, le café robusta, la canne à sucre, l’hévéa, le palmier à huile, la papaye et le riz pluvial présentent des scores médians quasi nuls sur l’ensemble du territoire, avec seulement quelques pixels littoraux très faibles dans certains cas. Le cacao, le cocotier, le café arabica, le manioc, l’igname, le niébé, le coton et l’ananas montrent des signaux un peu plus visibles, mais ceux-ci restent fragmentaires, principalement littoraux, et surtout perceptibles sous ssp585 en 2071-2090.
Ce groupe joue donc un rôle de garde-fou dans l’interprétation. Le modèle ne transforme pas mécaniquement le réchauffement en aptitude tropicale généralisée. Pour ces cultures, les contraintes combinées de gel, de durée de croissance, d’humidité, de saisonnalité et parfois d’exigences thermiques trop strictes continuent de bloquer l’essentiel du territoire. Le cas du cacao, du bananier, du café robusta ou du palmier à huile est particulièrement utile pour l’article: ces cultures fonctionnent comme des bornes symboliques. Elles rappellent que la montée des températures ne suffit pas à produire un climat tropical au sens agronomique.
En revanche, les faibles signaux observés pour l’ananas, le manioc, l’igname, le niébé ou le coton sur certaines marges atlantiques, bretonnes, méditerranéennes ou corses indiquent que la frontière n’est pas fixe. Ces espèces ne rejoignent pas le noyau des cultures plausibles, mais elles contribuent à la gradation générale: entre les cultures thermophiles déjà crédibles et les cultures tropicales encore presque impossibles, existe une zone de transition où quelques espèces deviennent ponctuellement moins absurdes. C’est précisément cette hiérarchie qui rend l’exercice utile: la carte ne valide pas un fantasme tropical, elle trie les espèces selon leur degré de plausibilité climatique.








Matériels et méthodes
L’analyse a été conduite dans Google Earth Engine à partir de la collection NASA/GDDP-CMIP6, version Google Earth Engine du jeu NEX-GDDP-CMIP6 décrit par Thrasher et al. Les variables utilisées sont la température minimale journalière (tasmin), la température maximale journalière (tasmax) et les précipitations journalières (pr). Les données ont été agrégées en climatologies mensuelles pour quatre périodes: 1995-2014, 2021-2040, 2041-2060 et 2071-2090. Deux scénarios CMIP6 ont été analysés: ssp245, retenu comme scénario central ; ssp585 est utilisé ici comme scénario haut de sensibilité, l’usage des scénarios de type RCP8.5/SSP5-8.5 comme “business as usual” ayant été critiqué, tandis que les politiques actuelles sont plutôt évaluées autour de 2,6 °C de réchauffement en 2100. Les neuf modèles climatiques retenus sont ACCESS-CM2, CMCC-ESM2, CNRM-CM6-1, EC-Earth3, GFDL-ESM4, MIROC6, MRI-ESM2-0, NorESM2-MM et TaiESM1.
La température moyenne mensuelle a été approximée par la moyenne de tasmin et tasmax, après conversion de Kelvin en degrés Celsius. Les précipitations mensuelles ont été calculées à partir de pr, converti de kg.m-².s-¹ en mm.mois-¹. Le nombre annuel de jours de gel a été estimé comme la fréquence moyenne des jours où tasmin < 273,15 K, rapportée à une année.
Les cultures étudiées comprennent 25 espèces tropicales, subtropicales ou associées aux agricultures du chaud: sorgho, mil, maïs tropical, riz pluvial, arachide, sésame, niébé, pois d’Angole, patate douce, manioc, taro, igname, coton, canne à sucre, mangue, avocat, ananas, papaye, bananier, café arabica, café robusta, cacao, cocotier, palmier à huile et hévéa. La logique de seuils d’aptitude suit la méthode Ecocrop, discutée par Ramírez-Villegas et al. Pour chaque culture, les seuils climatiques ont été extraits de la base Ecocrop ditribuée par OpenCLIM. Les champs utilisés sont TMIN, TOPMN, TOPMX, TMAX, RMIN, ROPMN, ROPMX, RMAX, GMIN, GMAX et ALTMX, correspondant aux limites et optimums de température, de précipitation, de durée de croissance et d’altitude.
Pour chaque culture, pixel, modèle, scénario et période, un score d’aptitude climatique compris entre 0 et 100 a été calculé. Les composantes thermique et hydrique reposent sur des fonctions trapézoïdales: score nul hors des limites minimales et maximales, score maximal dans l’intervalle optimal, interpolation linéaire entre les deux. Le score saisonnier correspond au minimum entre les scores thermique et hydrique. Les mois de départ possibles de la saison de croissance ont été testés. Dans la configuration utilisée ici, une seule durée de croissance est retenue par culture: la moyenne de GMIN et GMAX, convertie en mois et bornée entre 1 et 12; lorsque GMIN ou GMAX vaut 0, une durée de 12 mois est utilisée. Le meilleur score obtenu parmi les mois de départ est conservé.
Deux pénalités multiplicatives ont ensuite été appliquées au meilleur score saisonnier. La pénalité de gel est calculée à partir du nombre annuel moyen de jours avec tasmin < 0 °C. Pour chaque culture, deux paramètres ajoutés au modèle sont définis: frostHard, nombre de jours de gel tolérés sans pénalité, et frostFade, largeur de transition au-delà de ce seuil. La pénalité vaut 1 lorsque le nombre de jours de gel est inférieur ou égal à frostHard, décroît linéairement entre frostHard et frostHard + frostFade, puis vaut 0 au-delà. Formellement: Pgel = clamp((frostHard + frostFade - frostDays) / frostFade, 0, 1). Une pénalité altitudinale est également appliquée à partir de l’altitude maximale ALTMX issue d’Ecocrop et du modèle numérique de terrain SRTM (USGS/SRTMGL1_003). Elle vaut 1 jusqu’à ALTMX, décroît linéairement entre ALTMX et ALTMX + 300 m, puis vaut 0 au-delà: Palt = clamp((ALTMX + 300 - elevation) / 300, 0, 1). Le score final est donc Score = Score_saisonnier × Pgel × Palt, borné entre 0 et 100. Ces deux pénalités ne proviennent pas directement d’Ecocrop; elles ont été ajoutées pour éviter que des cultures sensibles au froid ou à l’altitude soient artificiellement favorisées en France métropolitaine.
Les scores ont été calculés séparément pour chaque modèle climatique, puis agrégés entre modèles. Les figures présentent principalement la médiane inter-modèles. Cette procédure évite de calculer l’aptitude sur un climat moyen multi-modèles, ce qui serait inadapté à un modèle à seuils. Les résultats décrivent une plausibilité climatique et non une faisabilité agronomique complète: ils ne tiennent pas compte des sols, de l’eau réellement disponible, des filières, des bioagresseurs, des pratiques agricoles, des marchés ou des réglementations.
Disclaimer
Je suis salarié du CIRAD, mais ce billet est publié à titre personnel. Il ne constitue pas une communication institutionnelle et ne reflète pas nécessairement la position du CIRAD. Les cartes présentées sont une exploration agroclimatique indicative, fondée sur des données ouvertes. Elles ne constituent pas des recommandations culturales et ne préjugent pas de la faisabilité agronomique, économique ou sociale des cultures évoquées.