Dans ma démarche progressive de dégooglisation, je me suis attaqué récemment à un gros morceau : Google Docs et Google Drive. L’idée pour moi est de passer à un autre fournisseur cloud. Mais pour les documents Google Docs/Sheets/Slides, un piège subtil de l’écosystème Google lié au format spécifique des fichiers rend difficile leur sauvegarde externe.
Le problème : L’illusion des fichiers locaux
Si vous utilisez le logiciel « Google Drive pour ordinateur » (qui vous monte par exemple un lecteur G: sous Windows), vous avez l’impression que vos fichiers sont là. Vous voyez MonProjet.gdoc ou Compta.gsheet.
Mais essayez de copier ces fichiers (typiquement, lancer une copie miroir par exemple avec un bon vieux FreeFileSync des familles) sur un disque externe ou un autre volume, ce fichier refusera d’être copié. De plus, même si la copie était possible, aucune données utilisable dedans car ce ne sont que des raccourcis JSON de quelques octets pointant vers le web. Du coup, si je coupe mon compte Google demain, je perds le contenu de ces fichiers.
Pour récupérer mes données, j’avais deux choix officiels, tous deux frustrants :
Google Takeout : pas de Takeout disponible pour le triptyque Docs/Sheets/Slides, mais seuleent un export de l’intégralité du Drive, autrement dit une « soupe » de fichiers zippés dans lesquels je ne suis même pas sûr que la rétroconversion en des fichiers « tangibles » aura été faite .
L’export manuel : Ouvrir chaque fichier un par un, faire Fichier > Télécharger > Microsoft Word. Pour 10 documents, ça va. Pour 500 documents archivés depuis 10 ans, c’est impossible.
La solution : un script d’export
Je voulais une solution qui :
Parcourt mes dossiers existants sur mon volume Google Drive
Convertit chaque fichier Google (Docs, Sheets, Slides) en son équivalent Office (docx, xlsx, pptx).
Enregistre le fichier converti exactement au même endroit, à côté de l’original (avec un petit suffixe dans son nom pour préciser son origine).
J’ai donc vibe codé sans honte un script PowerShell qui automatise tout ça via l’API Google Drive.
Avant de vous lancer, une limitation technique imposée par Google : Drive refusera de convertir les fichiers trop volumineux. Concrètement, si vous avez une présentation (.gslides) remplie d’images haute définition qui ferait plus de 10 Mo une fois convertie en .pptx, l’exportation échouera. Google coupe la connexion (TimeOut) car la conversion demande trop de ressources sur leurs serveurs.
Donc :
Le script fonctionnera parfaitement pour 95% de vos fichiers (textes, tableurs, présentations légères).
Pour les « gros » fichiers (thèses avec images, présentations marketing lourdes), le script affichera une erreur.
Solution : Ces quelques fichiers devront être ouverts dans le navigateur et téléchargés manuellement (Fichier > Télécharger). C’est le seul moyen.
Tuto : libérez vos données
Ce script utilise l’API officielle. C’est la méthode la plus propre, mais elle demande 5 minutes de configuration initiale.
Étape 1 : Créer vos accès API (OAuth)
Pour que le script puisse « discuter » avec votre Drive, vous devez créer une « application » dans la console Google.
Créez un Nouveau Projet (nommez-le ExportDrivePerso).
Dans API et services > Bibliothèque, cherchez et activez l’API Google Drive API.
Dans l’onglet Écran de consentement OAuth :
Choisissez Externe.
Remplissez le nom et votre email.
Important : Dans la section Utilisateurs tests, ajoutez votre propre adresse Gmail. C’est indispensable pour que cela fonctionne sans validation Google.
Dans Identifiants > Créer des identifiants > ID client OAuth :
Type : Application de bureau.Validez. Copiez votre ID Client et votre Code Secret Client.
Le script inclut une « recherche floue » (pour trouver les fichiers même si Windows gère mal les caractères spéciaux) et une gestion d’erreur spécifique pour vous signaler les fichiers trop gros.
Étape 3 : Lancer l’export
Ouvrez un terminal PowerShell et lancez la commande suivante (en adaptant les chemins et identifiants) :
Le script va parcourir vos dossiers. Vous verrez défiler des -> OK verts pour la majorité des fichiers. Vous verrez peut-être quelques -> ECHEC (Trop volumineux) en magenta. Notez-les : ce sont ceux que vous devrez traiter à la main. Au final, vous obtiendrez des fichiers Rapport_from_gdocs.docx directement exploitables.
Vos données sont enfin libérées et prêtes à être sychronisées avec votre nouveau cloud souverain !
Les équipes de Google DeepMind ont annoncé récemment la sortie d’un jeu de données d’observation de la Terre novateur, issu de l’assimilation d’une variété de données satellitaires de différents capteurs au sein d’un modèle de fondation. Sans entrer dans les détails (un post sur Medium1 et la documentation technique2 le font très bien), ce jeu de données, baptisé « Satellite Embedding », compresse l’information spectrale et radar d’une année entière d’observations en un vecteur à 64 dimensions, livré à 10 mètres de résolution. Autrement dit : chaque pixel de 10 × 10 m contient 64 valeurs qui résument tout ce qui a été observé par les satellites sur une année donnée.
Fig.1 : Représentation schématique animée de processus d’embedding des données d’observation de la Terre par satellite (source)
Ce qui est rigolo, c’est qu’on n’a aucun a priori sur ce que peut représenter chacune de ces dimensions dans le monde physique, contrairement, par exemple, à la bande 2 de Sentinel-2, d’une longueur d’onde de 490 nm et liée au spectre d’absorption de la chlorophylle, ou à la rétrodiffusion radar de Sentinel-1, sensible à l’angle de la pente des reliefs. Pire encore, on ne sait pas comment l’information temporelle est encodée : est-ce que la date d’une augmentation du NDVI, que l’on sait reliée à la croissance d’un couvert végétal, sera portée par une ou plusieurs composantes du vecteur ?
Le jeu satellite embeddings agrège donc une année d’observations multi-capteurs (optique + radar) en vecteurs latents ; on n’interprète pas chaque dimension physiquement, mais ces représentations condensent des motifs multi-sources et multi-temporels du couvert observé (structure, textures, phénologie, mosaïques d’occupation des sols) à la résolution des données d’entrée. Elles sont ainsi de bons proxies de l’état actuel du paysage, sans garantir qu’une dimension unique corresponde à un processus écologique précis.
Dans tous les cas, on sait que ce jeu de données contient une quantité phénoménale d’information, à une résolution très intéressante pour bon nombre d’applications.
Pourquoi cette note ?
Une des applications que j’aimerais explorer, c’est la cartographie d’espèces végétales. Et dans ce post, c’est justement une exploration rapide de cette idée que je présente.
Assez classiquement, la cartographie d’espèces passe par des approches de modélisation. Pourquoi modéliser ? Parce qu’il est difficile d’échantillonner l’espace assez finement pour dessiner des cartes « à la main ». On s’appuie donc sur des variables environnementales, généralement bien décrites et disponibles à bonne résolution spatiale et temporelle, pour estimer la probabilité de présence d’une espèce donnée. On peut pour cela mobiliser les paramètres écologiques/édaphiques de l’espèce (par ex. intervalles de température, pluviométrie annuelle, types de sols préférentiels, pente, altitude, etc.) afin d’identifier où l’espèce peut survivre et prospérer. C’est l’approche utilisée notamment par EcoCrop (FAO)3, centré en partie sur des espèces d’intérêt agronomique.
Quand ces paramètres sont mal connus ou incomplets, on peut adopter une approche fondée sur les données : on utilise des relevés botaniques qui indiquent la présence (l’absence étant, par définition, plus délicate à établir) à un endroit donné, on associe ces positions aux covariables au même endroit, puis on calibre des modèles de distribution d’espèces (Species Distribution Models, SDMs) pour extrapoler la probabilité de présence ailleurs. Il existe plusieurs modèles ; l’un des plus populaires est MaxEnt (pour « Maximum Entropy », le principe mathématique sur lequel il repose).
Pourquoi ce détour ? Parce que si l’on peut utiliser des variables environnementales spatialisées dans des SDMs pour estimer la répartition d’une espèce, il n’y a aucune raison de ne pas essayer un produit comme les Satellite Embeddings, qui résument une quantité considérable d’information observable depuis l’espace.
Distinction importante : alors que l’utilisation de variables environnementales permet surtout de définir où l’espèce pourrait se trouver (aire de répartition potentielle), les satellite embeddings pourraient, en principe, aider à répondre à où l’espèce se trouve aujourd’hui, car ils proviennent en grande partie d’observations directes du couvert végétal (signal « actuel »).
Je présente donc ci-après quelques essais rapides utilisant les satellite embeddings comme covariables dans un SDM MaxEnt, pour prédire la probabilité d’occurrence de quelques espèces végétales en Martinique.
Données et méthodes
Je commence par récupérer les satellite embeddings. Pour défricher rapidement, j’en fais l’extraction en GeoTIFF depuis Google Earth Engine, à une résolution dégradée à 100 m (agrégation par moyenne).
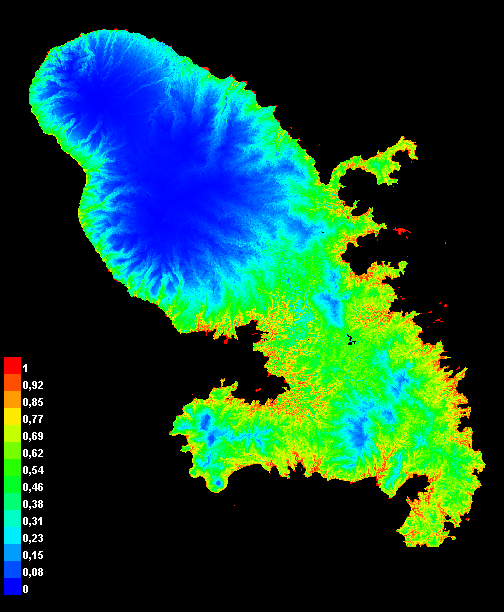
Fig. 2 : Composite trois couleurs des trois premières dimensions des satellite embeddings pour la Martinique (100 m). La discrimination des occupations de sol est déjà très visible — on dirait un minéral sous filtre polarisant ?
Trois espèces m’intéressent ici : l’arbre à pain (Artocarpus altilis) et le cocotier (Cocos nucifera) — parce que différences d’étagements, parce que des collègues s’y intéressent, et parce qu’on dispose d’un nombre d’observations important (n=341 et n=181 respectivement) — ainsi que la fleur boule montagne (Lobelia conglobata), endémique stricte de la Martinique, pour laquelle les observations sont bien moindres (n=64) et sur un étagement bien plus élevé.
Pour entraîner un SDM MaxEnt4, il faut des présences. Je lance donc des requêtes sur GBIF5 et iNaturalist6. Face aux 64 dimensions du jeu Satellite Embeddings (satemb), ce volume paraît suffisant pour une première exploration en limitant le risque de mal-conditionnement.
Avec un peu de Python (et un soupçon de magie noire), je prépare les fichiers d’entrée du SDM : les variables satemb, mais aussi des variables environnementales (env) — Tmin/Tmax/Tmoy annuelles (interpolation Météo-France 2023), pluie annuelle (stations DIREN + Météo-France, 7), altitude, pente, aspect, rugosité dérivées du SRTM/Copernicus 30 m, sur même zone d’étude, même grille 100 m et masque terrestre pour tous les rasters. J’entraîne ensuite MaxEnt v3.4.4 sur trois jeux de covariables : satemb, env et satemb+env, avec une validation croisée en cinq plis ; les chiffres reportés sont des moyennes ± écart-types de ces 5 plis.
L’ensemble des scripts et données pour répliquer l’analyse (et en lancer d’autres) est mis à disposition sur Zenodo : 10.5281/zenodo.16994138.
Résultats
Pour l’arbre à pain (A. altilis, Fig. 3), le modèle fondé sur les satellite embeddings seuls obtient l’AUC la plus élevée (0,833 ± 0,029), devant le modèle env (0,661 ± 0,044), soit un écart absolu de +0,172. Le modèle mixte est à 0,803 ± 0,055, donc en dessous de satemb. À grille identique (100 m) pour tous les prédicteurs, ces résultats suggèrent que les indices satellitaires condensés par les embeddings discriminent mieux les présences du fond que les seules variables abiotiques utilisées embarquées dans le modèle env. L’ajout des variables environnementales n’apporte pas de gain mesurable dans ce cas (probable redondance d’information + complexité accrue).
Pour le cocotier (C. nucifera, Fig. 4), l’écart entre satemb et env est plus faible que chez l’arbre à pain : 0,833 ± 0,036 contre 0,767 ± 0,045, soit +0,066 d’AUC pour satemb. Le mixte atteint 0,809 ± 0,045, intermédiaire entre les deux. Ici, les variables abiotiques (p. ex. altitude, pluie) portent déjà une part substantielle du signal, et les embeddings ajoutent un surcroît d’information sans toutefois dépasser nettement la combinaison.
PourL. conglobata (Fig. 5, espèce localisée en altitude en Martinique), les deux approches sont très performantes et la combinaison progresse encore : satemb 0,907 ± 0,015, env 0,906 ± 0,059, et mixte 0,933 ± 0,046 (soit +0,026 vs satemb). Lecture possible : l’enveloppe abiotique (altitude, exposition, humidité) cadre déjà bien la niche, et les embeddings ajoutent des indices d’occupation actuelle du paysage (structure de canopée, mosaïques agri-urbaines, phénologie), d’où un gain quand on les combine. A noter cependant un nombre d’observations retenues par le modèle (neff) particulièrement réduit, lié au regroupement des occurrences d’un même pixel, ce qui invite à considérer ces résultats avec prudence.
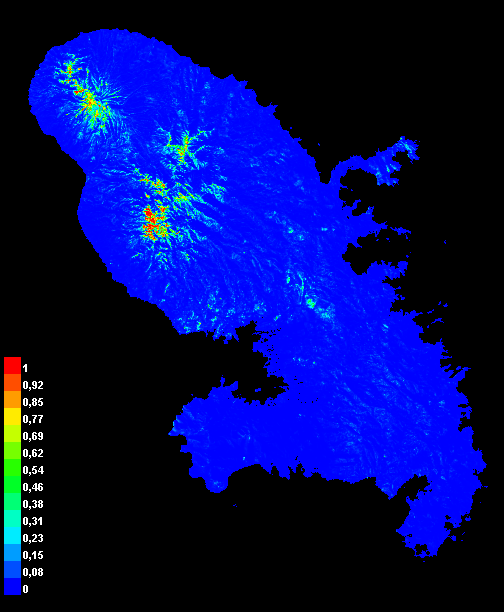
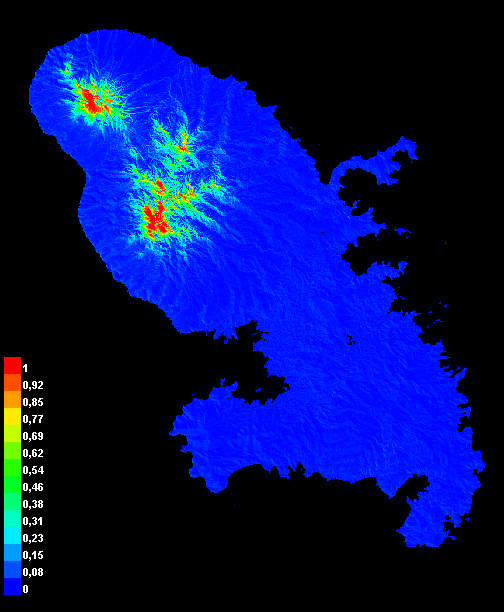
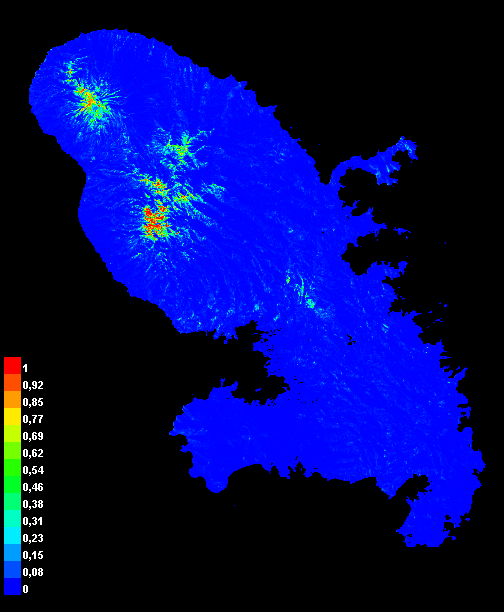
Fig. 3 : Résultats MaxEnt pour A. altilis, probabilité moyenne de présence cloglog sur les 5 plis. Gauche : modèle satemb, centre : modèle env, droite : modèle satemb+envFig. 4 : idem fig. 3 pour C. nuciferaFig. 5 : idem fig. 3 pour L. conglobata
satemb
env
satemb+env
A. altilis (neff = 168)
0,833 (± 0,029)
0,661 (± 0,044)
0,803 (± 0,055)
C. nucifera (neff = 78)
0,833 (± 0,036)
0,767 (± 0,045)
0,809(± 0,045)
L. conglobata (neff = 31)
0,907 (± 0,015)
0,906 (± 0,059)
0,933 (± 0,046)
Tab. 1 : Valeur moyenne de l’AUC pour la courbe ROC sur le set de test après 5 plis. neff : nombre effectif de présences après regroupement 1 point / pixel.
En lecture conceptuelle, l’approche env définit une enveloppe abiotique (où l’espèce pourrait vivre), tandis que l’approche satemb fournit des indices d’occupation actuelle (où le paysage ressemble aujourd’hui aux sites observés), complémentarité visible en Fig. 3–4 ; le modèle mixte (env+satemb) approxime l’intersection de ces deux informations — conditions favorablesETindices compatibles — sans pour autant conclure à une « présence certaine ». Pour l’exploiter, on peut envisager de croiser les deux surfaces après choix d’un seuil validé en CV (p. ex. 10è centile des présences) et l’on cartographie trois classes : Potentiel ? Présent (cœur réalisé), Potentiel \ Présent (réservoir latent) et Présent \ Potentiel (hors enveloppe) ; l’intérêt est alors bien de lire les modèles ensemble plutôt que d’interpréter chaque carte isolément.
Limites et discussion
Cette approche exploratoire souffre néanmoins d’un certain nombre de limites :
Échantillonnage des présences
Echatillonage participatif et biais d’accessibilité (proximité routes/bourgs) non pondéré ; pas de bias file / target-group background utilisé.
Pas de thinning spatial : malgré le “1 point par pixel” implicite de MaxEnt, des clusters peuvent subsister et peuvent biaiser l’ajustement.
Covariables et échelle
Embeddings : approche boîte noire ? interprétabilité limitée variable par variable ; forte colinéarité possible entre dimensions : feature engineering/PCA/UMAP pour tester si 10–15 composantes suffisent ?
Variables env : jeu réduit (pas de sols notamment) ; d’autres facteurs abiotiques/édaphiques non pris en compte.
Résolution unique 100 m choisie pour la praticité volume de données/temps de calcul : sensibilité à l’échelle (i.e. 30m natif SRTM vs 100m, etc.) non évaluée.
Paramétrage et protocole d’entraînement
Régularisation non optimisée (valeurs par défaut) ; pas de sélection parcimonieuse des prédicteurs. MaxEnt ? processus ponctuel de Poisson régularisé : régler la pénalité et les feature classes limite le sur-apprentissage, surtout avec 64 dims.
Cohérence temporelle
Présences multi-années non synchronisées avec les covariables : acceptable ici (espèces pluriannelles à pérennes), mais pour des annuelles il faudrait aligner l’année d’observation avec l’année des variables.
Validité et portée des résultats
CV spatiale en blocs (au lieu de k-fold aléatoire) pour limiter l’optimisme lié à l’autocorrélation et tester la transférabilité spatiale.
L’AUC (définie ici via “predicted area” au sens MaxEnt) est utile mais peut être indulgente en présence d’autocorrélation spatiale et de prévalence très faible.
Conclusions dépendantes de l’espèce, de la zone et de l’échelle ; transférabilité non testée.
Ces limites n’invalident pas fondamentalement les tendances observées, cependant, elles bornent la portée des résultats et indiquent les priorités d’amélioration pour une itération suivante.
Conclusion
À emprise et résolution communes (100 m), les satellite embeddings apportent un signal propre exploitable en SDM : ils suffisent à eux seuls pour distinguer les présences du fond sur deux espèces testées (A. altilis, C. nucifera), et, pour L. conglobata, la combinaison avec les variables abiotiques montre un léger mieux — à confirmer compte tenu du neff réduit et de la CV non spatiale. Le signal porté par ces représentations latentes — proxys d’observations multisources du couvert à 10 m — est donc complémentaire des gradients climato-topographiques : parfois suffisant seul, souvent utile en appui selon le profil écologique.
Méthodologiquement, ces résultats suggèrent un workflow pragmatique : (i) considérer les embeddings comme baseline forte, (ii) n’ajouter que quelques variables abiotiques non redondantes quand l’écologie l’exige, et (iii) fiabiliser par CV spatiale, régularisation et correction du biais d’échantillonnage. Au-delà de l’AUC, des indicateurs comme le Continuous Boyce Index, le partial ROC et des cartes MESS aideront à juger robustesse, calibration et extrapolation.
Enfin, parce que les embeddings sont disponibles par année, ils ouvrent des perspectives pratiques (à tester) : suivi interannuel de l’aire effectivement occupée, détection de déplacements (expansion/contraction), mise en évidence de foyers « hors enveloppe » (plantations, micro-refuges) et priorisation de prospections (zones « potentiel haut ? présent haut »). Cela plaide pour des SDM opérationnels où les embeddings jouent un rôle central, en propre ou en complément de l’abiotique.
Steven J. Phillips, Miroslav Dudík, Robert E. Schapire. [Internet] Maxent software for modeling species niches and distributions (Version 3.4.1). Available from url: http://biodiversityinformatics.amnh.org/open_source/maxent/. Accessed on 2025-8-29. ↩︎
Comme vous le savez peut-être, j’aime les trucs qui volent (voir ici, là, et là aussi). Et comme vous le savez peut être madame et moi sommes pilotes ULM – vous savez, ces petits avions légers, et depuis peu propriétaires d’une superbe machine tout alu et toute rutilante.
Je me suis rendu compte d’un truc assez simple : dans l’ULM, les choses intéressantes arrivent souvent “entre deux posts”. Un retour d’expérience qui vaut de l’or, une discussion technique qui répond pile à ta question, une actu importante, une vidéo vraiment utile… et toi tu la vois trois semaines plus tard, au hasard d’un scroll.
Sauf que je n’avais pas envie de passer ma vie à surveiller 12 sites, 4 forums et une montagne de vidéos “au cas où”.
Alors j’ai fait un truc, Robbie l’Aviateur, un copilote qui me dit “hé, cette semaine, voilà ce qui vaut le détour”.
Du coup, c’est quoi Robbie l’Aviateur ?
C’est une newsletter hebdomadaire ULM (envoyée le mercredi soir) qui résume l’essentiel :
ce qui a fait parler la communauté,
les questions et débats techniques récurrents,
les actus et sujets terrain,
et quelques contenus qui ressortent (forums / vidéos / etc.).
En pratique, au lieu de tout suivre, ce sont des LLM qui lisent l’actu à ma place, et je reçois un résumé avec les sources.
Mais en en parlant des actus à l’aéroclub, je me suis dit que je n’étais probablement pas le seul à vouloir gagner du temps, rester à jour, et tomber plus souvent sur les pépites.
Donc je l’ai mis en ligne et j’ouvre l’inscription.
C’est encore en construction. Robbie est un projet vivant : je l’améliore au fil des semaines. Il peut rater un contexte, simplifier trop, ou passer à côté d’un sujet — et justement, vos retours m’aident à l’affiner. Si vous voulez proposer des sources, un format, une rubrique, ou signaler un point : je prends.
Si vous naviguez dans les eaux parfois troubles du doctorat sous statut CIFRE, une récente évolution législative mérite votre attention. Jusqu’à présent, la question du droit à la prime de fin de contrat (aka « prime de précarité ») pour les doctorants en CDD CIFRE pouvait être un véritable casse-tête, certains employeurs refusant son versement, via des interprétations du code du travail aussi variées que contradictoires d’un tribunal à l’autre. Tout pourrait changer avec la loi de programmation de la recherche (LPR) n° 2020-1674 du 24 décembre 2020, qui pourrait apporter des clarifications bienvenues.
La LPR a en effet modifié le paysage des contrats doctoraux, en ajoutant notamment un nouvel article au code de la recherche (L412-3) qui définit la notion de « contrat doctoral de droit privé », précisant de fait les contours des contrats sous convention CIFRE. Aussi, l’article 6 de la LPR complète l’article L. 1242-3 du code du travail – souvent cité dans les décisions des tribunaux – en y intégrant explicitement les contrats doctoraux de droit privé.
L’un des points les plus saillants de cette LPR concerne donc la prime de fin de contrat. Avant cette loi, les entreprises pouvaient décider de ne pas verser cette prime (correspondant, précisons-le, à 10% du salaire brut sur la durée du contrat soit 7000 €), sans que le cadre légal ne leur oppose de véritable résistance. Les choses semblent changer, car l’article 6 stipule désormais clairement que les indemnités de fin de contrat ne sont pas dues en cas de rupture anticipée du contrat pour cause de non-réinscription du doctorant.
En définissant explicitement les conditions dans lesquelles la prime n’est pas due, l’esprit de la loi suggère que dans tous les autres cas, cette prime devrait être versée. Cette précision a le mérite de commencer à sortir la question de la prime de fin de précarité de la zone grise où elle se trouvait – une zone grise d’une certaine taille : voir le blog « Cifre et précarité » qui documente le parcours d’un doctorant, et liste de décisions de cour d’appel d’autres candidats. Cette évolution est notable car elle semble refléter une volonté législative de mieux protéger les doctorants sous contrats doctoraux de droit privé, en leur assurant une reconnaissance et une sécurité accrues.
Cependant, et il est important de le souligner, mon propos n’est pas de fournir une interprétation juridique définitive mais plutôt de signaler une tendance qui pourrait être favorable aux doctorants. C’est une interprétation qui mériterait d’être explorée et discutée, notamment avec l’aide d’un juriste spécialisé, pour en comprendre pleinement les implications et faire valoir les droits des doctorants.
C’est donc une évolution à suivre de près, et pour ceux qui sont directement concernés, il pourrait être judicieux de se renseigner davantage sur ces changements et, si nécessaire, de consulter un professionnel pour évaluer l’impact sur leur situation spécifique.